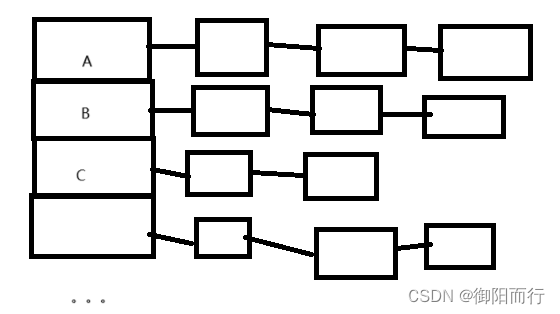
1. 基本分析
拉普拉斯金字塔分解,主要由以下步骤组成:
- 对输入图像 L0 进行低通滤波,其中常采用高斯滤波;
- 对低通滤波后的图像进行 1/2 倍率的下采样,这里的下采样通常是指直接取偶行且偶列(以 0 开始计)的像素,获得低频图像 L1;
- 对低频图像 L1 进行 2 倍的插零上采样,等价于直接将第 1 步的低通滤波图像的奇行或奇列像素置零;
- 对第 3 步上采样所得图像进行低通滤波,注意此处的低通滤波方法可与第 1 步的不一样;
- 输入图像减去第 4 步的低通滤波图像,即可获得输入图像的高频图像 H0;
- 如果对第 2 步所得低频图像 L1 重复以上步骤,即可获得 L1 的低频图像 L2 与高频图像 H1;
- 因为 H0 的尺寸为输入尺寸,H1 的尺寸为输入尺寸的 1/2x1/2,L2 的尺寸为输入图像的 1/4x1/4,将 H0, H1, L2 按顺序堆叠起来,就形成一个金字塔的形状,我们称之为拉普拉斯金字塔;如果对 L2 继续分解,还可获得更高层次的金字塔;
- 仅凭 H0, H1, L2 就能无损地恢复输入图像 L0,这是显而易见的,将 L2 进行插零上采样以及与第 4 步相同的低通滤波后,与 H1 相加即可无损恢复到 L1,同理即有 L0;
- 因为 H0 是 L0 的高频,H1 是 L1 的高频,L2 是 L1 的低频,我们可以将 H0,H1, L2 分别称为输入图像的高频、中频、低频分量。
在以上拉普拉斯金字塔分解方法中,具体低/中/高频的意义并没有定量的描述。为此,我们可以基于傅里叶变换进行分析,因为以上的步骤都可以在频域通过简单的处理得到等价的结果。

首先看第 1 步低通滤波的必要性,因为在硬件中低通滤波需要用到 linebuffer,如果能够不滤波直接下采样是最好的。如图 1 所示,上行的左列是输入图像,这里为了突出高频分量的变化使用了比较极端的示例,中列是左列直接(不进行低通滤波)下采样再上采样的图像,其中只有偶行且偶列的像素是有效的,右列是左列偶行且偶列像素组成的图像,通过补零填充到一样的大小;下行的左列图像则是输入图像经过高斯低通滤波的结果,中列和右列的处理和上行一样。图 2 是图 1 各图像对应的离散傅里叶变换(DFT)结果,其中每个 DFT 图像的中心对应着低频分量,越往外则是高频分量,越亮代表越大的幅度。这里的频域分析涉及到一些数字信号处理的知识。简单地说,经过下采样以及上采样,中列图像的 DFT 是左列图像 DFT 经过 1/2 周期延拓并叠加的结果,这就会导致图像的高频分量部分发生混叠,造成一定的信号失真;右列图像的 DFT 是中列图像 DFT 中心 1/4 区域放大两倍的结果。

因为高斯滤波等价于在频域中与高斯函数相乘,所以输入图像经过低通滤波后,其高频分量有所衰减,可以从图 2 左下角看到一个弥散圆的轮廓,其半径由高斯滤波核的方差决定,方差越大也就是滤波核半径越大,此时频域中的弥散圆半径反而越小,即有更多的高频分量被衰减。可以看到,原图像(左上角)由于纹理比较丰富,所以在高频区域也有较大的幅度。如果不进行低通滤波而直接下采样(右上角),其 DFT 相比于低通滤波后下采样(右下角)可以保留更多的高频分量,这似乎是更好的选择。但问题在于,右上角虽然保留了更多的高频分量,但相较于左上角(原图)有很大一部分高频分量是不一致的,这首先要明白右列的 DFT 只是中列 DFT 中心 1/4 区域放大的结果,也就是说左列 DFT 中心 1/4 区域以外的高频分量已经被混叠到中心 1/4 区域而消失了。对于右下角,尽管高频分量损失了很多,但正因此没有因为下采样而发生混叠,我们看到的只是一幅相对模糊的图像;而对于右上角,因为混叠而可能出现高频分量一部分被衰减而另一部分被增强的情况,反而会导致图像产生很多意想不到的伪纹理,其中主要是锯齿等等。因此,我们倾向于在下采样前首先进行低通滤波。
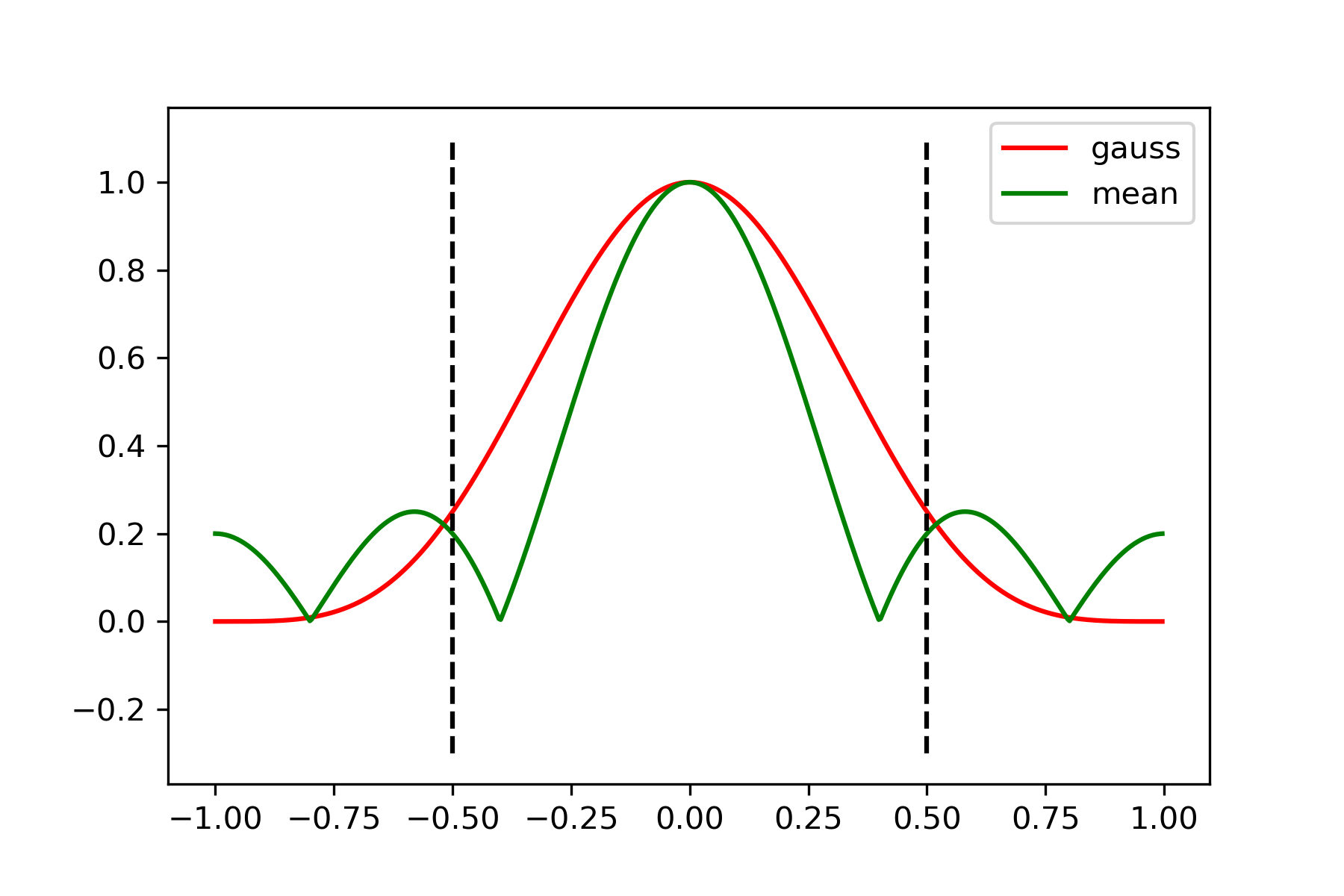
不过要注意的是,即便我们不进行低通滤波而直接下采样,也照样可以执行拉普拉斯分解的余下步骤,得到相应的高频图像。只要高频图像的内容不发生改变,我们就可以无损地恢复到原图像,和下采样之前是否进行低通滤波并无关系。但问题也出在此处,例如当我们需要进行图像降噪的任务时,高频分量往往是被抑制的,而最极端的情况就是拉普拉斯分解所得的高频图像完全被消除,那么重构图像只取决于下采样所得图像,这自然地又回到了前面所说的高频混叠问题。因此从实际应用的角度出发,下采样之前的低通滤波是必不可少的。另外要注意的是,低通滤波的具体实现有很多种选择,常用的包括高斯滤波与均值滤波等等。高斯滤波的优点在于其在频域同样是高斯函数,因此其幅度曲线十分平滑,不会出现均值滤波所具有的高频区域震荡;缺点是在同样的滤波核长度下对于中低频分量的衰减幅度要低于均值滤波。关于滤波核长度为 5 的高斯滤波与均值滤波的频谱曲线如图 3 所示。
在理解了为什么要在下采样之前进行低通滤波后,我们还要理解拉普拉斯分解第 4 步中为什么上采样后还要进行一次低通滤波。回到图 1,经过第 3 步的上采样后,我们得到的图像的奇行或奇列都是 0,这时我们不能直接与原图像相减,否则得到的结果就是偶行且偶列的像素几乎为 0,而奇行或奇列的像素等同于原图像像素,因此我们需要一个插值的步骤。图像插值有很多种方法,包括最近邻插值、双线性插值等等,但是这些插值方法对于频域的分析不太方便。如果对数字信号处理比较熟悉,我们就知道离散信号可通过低通滤波实现线性内插。具体地,我们可以发现图 2 的中列图像的 DFT 中心 1/4 区域与左列图像的 DFT 十分相像,只是在四个角落以及四边中点出现了与中心重复的 DFT 分量,而这些重复的 DFT 分量正是上采样图像的奇行或奇列为 0 的原因,因此我们只要使用一个理想的低通滤波器把重复的 DFT 分量去除,只保留中心 1/4 区域的 DFT 分量,就能把图 1 的中列图像恢复到左列图像,当然已经发生混叠的高频分量是无法恢复的。由于理想低通滤波器需要在频域进行操作,而在实际应用中我们不可能有足够的算力把图像转换到频域,所以一般在时域使用普通的低通滤波器即可,例如最常用的也是高斯滤波。

如图 4 所示,上行的左列及中列图像为图 1 下行的左列及中列,而右列为中列图像经过高斯滤波的结果,图中下行即为三者对应的 DFT 图像。可以看到,只需一个简单的高斯滤波,即可实现上采样图像中奇行或奇列像素的插值,得到的结果除了稍微模糊以外与下采样之前的图像并没有太大的区别,而稍微模糊的原因也是由于此处的高斯滤波同样会导致一部分的高频信号衰减。实际上,如前面所述使用其他的插值方法比如最近邻插值也是可行的,只是最近邻插值不是一种零相位滤波器,其对于频谱的影响要比高斯滤波等零相位滤波器要复杂得多,并且容易导致锯齿以及伪纹理的产生。实际上,如果考虑长度为 3 的高斯滤波核即 [1, 2, 1],我们可以发现此时高斯滤波插值的结果和双线性插值是一样的,这个只需简单推理即可。相比于双线性插值,高斯滤波的优点是可以轻松地扩展滤波核的长度,从而灵活地调整高频分量衰减的范围,当然代价就是其所需的计算复杂度要更高一些。至此,我们就理解了拉普拉斯分解第 4 步上采样后进行低通滤波的意义。

可以看到,拉普拉斯分解需要进行两次低通滤波,每一次滤波都会导致一部分高频分量衰减,因此第 5 步的原图像与最后一次低通滤波图像的相减就是要提取损失的高频分量。如图 5 所示,左列是原图像及其 DFT,中列是拉普拉斯分解第 4 步所得图像及其 DFT,右列是第 5 步所得高频图像及其 DFT。从右上角可以看出,高频图像主要对应着原图像的边缘和纹理,这是一个十分良好的性质,因为人眼主观感受系统往往更加喜欢锐利的边缘,所以我们在进行图像处理,如降噪时,可以对低频图像应用更高的降噪强度以获得更加平滑的背景,而对高频图像应用相对更弱的降噪强度,尽可能保证图像边缘细节的锐度,这样就能获得更好的主观降噪质量。实际上拉普拉斯分解的名字来自拉普拉斯算子,即二阶微分算子,对图像进行二阶微分同样能够实现边缘提取,因此我们常把能够提取图像边缘的方法称为拉普拉斯方法,尽管不一定需要用到二阶微分。
在很多应用中,单层的拉普拉斯分解并不满足我们对于不同尺度纹理的质量把控,这是因为有些大尺度的纹理在计算机看来也是属于低频内容。这里涉及到一个算法的可视域,也就是算法处理当前像素时能够访问的邻域像素的范围,当我们把图像不断缩小,算法的可视域就会越来越大,这样才能发现更多大尺度的信息。举个例子,一张白纸挡在面前,我们只会看到白茫茫的一片,没有任何细节,而当我们把白纸拿远一点,白纸占据的视野面积就会越来越小,最后我们就能发现白纸的四周是有边缘以及拐角的。因此,当我们完成单层的拉普拉斯分解后,如果对下采样所得低频图像继续分解,那么在继续分解所得的低频图像及高频图像上的算法处理,就等价于在一个更大的可视域上对原图像进行处理,这往往可以获得更好的主观效果,这就是为什么我们要使用拉普拉斯金字塔的原因。如图 6 所示,当我们进行两次拉普拉斯分解以后,分别可获得第一次分解所得高频图像 H0,第二次分解所得高频图像 H1,以及第二次分解所得低频图像 L2,它们的 DFT 图像刚好大致对应了原图像 DFT 的外沿带,中间带,以及中心区,也就是 H0 主要对应了原图像的极高频分量,H1 主要对应了原图像的中高频分量,L2 主要对应了原图像的中低频分量。由此,我们可简单地将 H0,H1,L2 分别称为原图像的高频、中频以及低频分量。

2. 测试脚本
# -*- coding: utf-8 -*-
import numpy as np
import cv2
def periodic_gaussian_blur(img, ksize, sigma=0, ktype=0):
kr = ksize // 2
h, w = img.shape[:2]
'''
# mannual wrap padding
tmp = np.zeros([h+2*kr, w+2*kr], dtype=img.dtype)
tmp[kr:h+kr, kr:w+kr] = img
tmp[kr:h+kr, :kr] = img[:, -kr:]
tmp[kr:h+kr, -kr:] = img[:, :kr]
tmp[:kr, :] = tmp[-2*kr:-kr, :]
tmp[-kr:, :] = tmp[kr:2*kr, :]
'''
tmp = np.pad(img, ((kr, kr), (kr, kr)), 'wrap')
if ktype == 0:
tmp = cv2.GaussianBlur(tmp, (ksize, ksize), sigma)
else:
tmp = cv2.boxFilter(tmp, -1, (ksize, ksize), normalize=True)
img = tmp[kr:h+kr, kr:w+kr]
return img
ksize = 5
sigma = 0
lvs = 2
img = cv2.imread('test2.png', 0).astype('float32') - 128
np.random.seed(0)
#img = img + np.random.randn(*img.shape) * 30
eps = 1e-15
vmax = 50000
freqs = []
valus = []
for i in range(lvs):
h, w = img.shape[:2]
fft_img = np.fft.fft2(img)
fft_img = np.fft.fftshift(fft_img)
abs_img = np.abs(fft_img)
abs_img = np.clip(abs_img + eps, 0, vmax)
dns1 = np.zeros_like(img)
dns1[::2, ::2] = img[::2, ::2] * 4
fft_dns1 = np.fft.fft2(dns1)
fft_dns1 = np.fft.fftshift(fft_dns1)
abs_dns1 = np.abs(fft_dns1)
abs_dns1 = np.clip(abs_dns1 + eps, 0, vmax)
dns2 = np.zeros_like(img)
dns2[:h//2, :w//2] = img[::2, ::2] * 4
fft_dns2 = np.fft.fft2(dns2)
fft_dns2 = np.fft.fftshift(fft_dns2)
abs_dns2 = np.abs(fft_dns2)
abs_dns2 = np.clip(abs_dns2 + eps, 0, vmax)
gau = periodic_gaussian_blur(img, ksize, sigma)
fft_gau = np.fft.fft2(gau)
fft_gau = np.fft.fftshift(fft_gau)
abs_gau = np.abs(fft_gau)
abs_gau = np.clip(abs_gau + eps, 0, vmax)
dng1 = np.zeros_like(gau)
dng1[::2, ::2] = gau[::2, ::2] * 4
fft_dng1 = np.fft.fft2(dng1)
fft_dng1 = np.fft.fftshift(fft_dng1)
abs_dng1 = np.abs(fft_dng1)
abs_dng1 = np.clip(abs_dng1 + eps, 0, vmax)
dng2 = np.zeros_like(gau)
dng2[:h//2, :w//2] = gau[::2, ::2] * 4
fft_dng2 = np.fft.fft2(dng2)
fft_dng2 = np.fft.fftshift(fft_dng2)
abs_dng2 = np.abs(fft_dng2)
abs_dng2 = np.clip(abs_dng2 + eps, 0, vmax)
disp1 = np.hstack((img, dns1, dns2))
disp2 = np.hstack((gau, dng1, dng2))
disp = np.vstack((disp1, disp2))
disp = np.clip(disp + 128.5, 0, 255).astype('uint8')
cv2.imwrite('img_down_{}.png'.format(i), disp)
disp1 = np.hstack((abs_img, abs_dns1, abs_dns2))
disp2 = np.hstack((abs_gau, abs_dng1, abs_dng2))
disp = np.vstack((disp1, disp2))
disp = np.clip(disp, 0, vmax)
disp = (disp / vmax * 255 + 0.5).astype('uint8')
cv2.imwrite('fft_down_{}.png'.format(i), disp)
upg1 = periodic_gaussian_blur(dng1, ksize, sigma)
fft_upg1 = np.fft.fft2(upg1)
fft_upg1 = np.fft.fftshift(fft_upg1)
abs_upg1 = np.abs(fft_upg1)
abs_upg1 = np.clip(abs_upg1 + eps, 0, vmax)
disp1 = np.hstack((gau, dng1, upg1)) + 128.5
disp2 = np.hstack((abs_gau, abs_dng1, abs_upg1)) / vmax * 255 + 0.5
disp = np.vstack((disp1, disp2))
disp = np.clip(disp, 0, 255).astype('uint8')
cv2.imwrite('gau_up_{}.png'.format(i), disp)
dif1 = img - upg1
fft_dif1 = np.fft.fft2(dif1)
fft_dif1 = np.fft.fftshift(fft_dif1)
abs_dif1 = np.abs(fft_dif1)
abs_dif1 = np.clip(abs_dif1 + eps, 0, vmax)
if i == 0:
freqs.append(abs_dif1)
valus.append(np.abs(dif1))
else:
freq = np.zeros_like(freqs[0])
valu = np.zeros_like(valus[0])
h0, w0 = freq.shape[:2]
freq[::(2**(i)), ::(2**(i))] = dif1 * (4**i)
fft_freq1 = np.fft.fft2(freq)
fft_freq1 = np.fft.fftshift(fft_freq1)
abs_freq1 = np.abs(fft_freq1)
abs_freq1 = np.clip(abs_freq1 + eps, 0, vmax)
freq *= 0
freq[h0//2-h//2:h0//2-h//2+h, w0//2-w//2:w0//2-w//2+w] = abs_freq1[h0//2-h//2:h0//2-h//2+h, w0//2-w//2:w0//2-w//2+w]
freqs.append(freq)
valu[h0//2-h//2:h0//2-h//2+h, w0//2-w//2:w0//2-w//2+w] = np.abs(dif1)
valus.append(valu)
if i == lvs - 1:
freq = np.zeros_like(freqs[0])
valu = np.zeros_like(valus[0])
freq[::(2**(i+1)), ::(2**(i+1))] = gau[::2, ::2] * (4**(i+1))
fft_freq1 = np.fft.fft2(freq)
fft_freq1 = np.fft.fftshift(fft_freq1)
abs_freq1 = np.abs(fft_freq1)
abs_freq1 = np.clip(abs_freq1 + eps, 0, vmax)
freq *= 0
freq[h0//2-h//4:h0//2-h//4+h//2, w0//2-w//4:w0//2-w//4+w//2] = abs_freq1[h0//2-h//4:h0//2-h//4+h//2, w0//2-w//4:w0//2-w//4+w//2]
freqs.append(freq)
valu[h0//2-h//4:h0//2-h//4+h//2, w0//2-w//4:w0//2-w//4+w//2] = gau[::2, ::2] + 128
valus.append(valu)
disp1 = np.hstack((img+128, upg1+128, np.abs(dif1))) + 0.5
disp2 = np.hstack((abs_img, abs_upg1, abs_dif1)) / vmax * 255 + 0.5
disp = np.vstack((disp1, disp2))
disp = np.clip(disp, 0, 255).astype('uint8')
cv2.imwrite('diff_{}.png'.format(i), disp)
img = gau[::2, ::2]
disp1 = np.hstack(tuple(valus)) + 0.5
disp2 = np.hstack(tuple(freqs)) / vmax * 255 + 0.5
disp = np.vstack((disp1, disp2))
disp = np.clip(disp, 0, 255).astype('uint8')
cv2.imwrite('diff_low.png', disp)